Bai Yang
| Since long ago, the high-layer architecture
at server end has been categorized into two contradictory patterns:
SOA (Service-oriented architecture) and AIO (All in one). SOA
divides a complete application into several independent services,
each of which provides a single function (such as session
management, trade evaluation, user points, and etc.). These services
expose their interfaces and communicate with each other through IPC
mechanisms like RPC and WebAPI, altogether composing a complete
application.
Conversely, AIO restricts an application within a separate unit. Different services within SOA behave as different components and modules. All components usually run within a single address space (the same process), and the codes of all components are usually maintained under the same project altogether. The advantage of AIO is simplified deployment, eliminating the need for deploying multiple services and implementing high availability clustering for each service. AIO architecture has far higher efficiency than SOA, because it can avoid huge consumptions caused by IPC communications like network transmission and memory copy. On the other hand, components within AIO are highly inter-dependent with poor reusability and replaceability, making maintenance and extension difficult. It is common that a rookie will spend a lot of effort and make many mistakes before getting the hang of a huge project which contains a large number of highly coupled components and modules. Even a veteran is prone to cause seemingly irrelevant functions being affected after modifying functions of a module, because of complicated inter-dependence among components. The SOA architecture features complex deployment and configuration. In real cases, a large application is usually divided into hundreds of independent services. For example, a famous e-commerce website (among the top 5 in China) which fully embraces SOA has divided their Web application into tens of hundreds of services. We can imagine the huge amount of workload required to deploy hundreds of servers within high availability environment where multiple active data centers exist, and to configure these servers to establish coordination relationships among them. For example, the recent network outage with ctrip.com was followed by slow recovery due to its huge SOA architecture which comprises tens of hundreds of services. Inefficient is another major disadvantage of SOA. From the logic flow perspective, almost every complete request from the client needs to flow through multiple services before the final result is generated and then returned to the client. Flowing through each service (through messaging middleware) is accompanied by multiple times of network and disk I/O operations. Thus several requests will cause long network delay accumulatively, resulting in bad user experience and high consumption of resources.
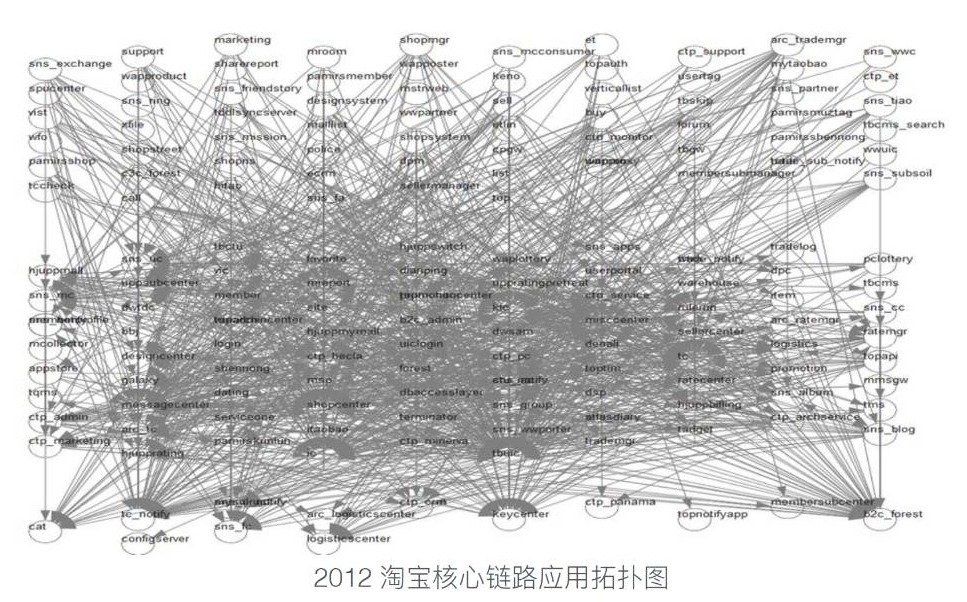
The Messy SOA Dependencies (Image from the Internet) The responsibility to implement the support for cross-service distributed transaction will fall on the application developers, no matter each service is connected to a different DBMS or all services are connected to the same distributed DBMS system. The effort for implementing distributed transaction itself is more complex than most of common applications. Things will become more difficult when we try to add high availability and high reliability assurance to it, to achieve this goal, developers need to: utilize algorithms like Paxos/Raft or master/slave + arbiter for a single data shard; and employ algorithms like 2PC/3PC for transactions comprised of multiple data shards to achieve the ACID guarantee. Therefore, a compromise solution for implementing cross-service transactions within SOA applications is to guarantee the eventual consistency. This also requires extensive efforts, because it is not easy to implement consistency algorithms in a complex system. Most of SOA systems usually need to utilize messaging middleware to implement message dispatching. This middleware can easily become a bottleneck if there are requirements for availability (part of nodes failed will not affect normal operation of the system), reliability (ensures messages are in order and never repeated/lost even when part of nodes failed), functionality (e.g., publish-subscribe pattern, distributing the tasks in a round-robin fashion) and etc. The strength of SOA architecture lies with its high cohesion and low coupling characteristics. Services are provided through predefined IPC interface, and are running in an isolated way (usually in a separate node). SOA architecture has set a clear boundary for interfaces and functions, thus services can be easily reused and replaced (any new services that have compatible IPC interface can replace existing services). From the point of view of software engineering and project management, each service itself has enough high cohesion, and its implemented functions are independent, SOA services are easier to maintain compared with interwoven AIO architecture. A developer only needs to take care of one specific service, and don't need to worry about any code modification or component replacement will affect other consumers, as long as there is no incompatible change to the API. An application composed of multiple independent services is easier to implement function modification or extension through the addition of new services or recombination of existing services. |
| Through extensive exploration and practice
with real projects, I have defined, implemented and improved the
nano-SOA architecture which incorporates the strengths of
both SOA and AIO. In nano-SOA, services that run independently are
replaced by cross-platform plugins (IPlugin) that support
hot-plugging. A plugin dynamically exposes (register) and hides
(unregister) its function interfaces through (and only through) API
Nexus, and consumes services provided by other plugins also through
API Nexus. nano-SOA fully inherits the high cohesion and low coupling characteristics of SOA architecture. Each plugin behaves like an independent service, has clear interface and boundary, and can be easily reused or replaced. It is comparable to SOA from the maintenance perspective. Each plugin can be developed and maintained separately, and a developer only needs to take care of his own plugin. By the addition of new plugins and recombination of existing plugins, nano-SOA makes things easier to modify or extend existing functions than SOA architecture. nano-SOA is comparable to AIO with regard to performance and efficiency. All plugins run within the same process, thus calling another plugin through API Nexus does not need any I/O or memory copy or any other forms IPC consumption. The deployment of nano-SOA is as simple as AIO. It can be deployed to a single node, and can achieve high availability and horizontal scaling by deploying only a single cluster. The configuration of nano-SOA is far simpler than SOA. Compared with AIO, configuring a list of modules to be loaded is the only thing added for nano-SOA. However, all the configurations for nano-SOA can be maintained in batch through utilizing a configuration management product. Streamlined deployment and configuration process can simplify operation and maintenance efforts, and also significantly facilitate establishing development and testing environments. By using direct API calling through API Nexus, nano-SOA can avoid the dependence on messaging middleware to the maximum extent. We can also improve the parallel computing performance by plugging an inter-thread message queue (which is optimized through zero-copy and lock-free algorithms) on it. This has greatly increased throughput, reduced delay, and also eliminated huge efforts required for deploying and maintaining a high availability message dispatching cluster. nano-SOA has minimized the requirement for inter-node cooperation and communication, not imposing high demand for reliability, availability and functionality. In most cases, decentralized P2P protocol such as Gossip is adequate to meet these requirements. Sometimes, inter-node communication can even be completely avoided. From the nano-SOA perspective, DBC can be considered as a type of fundamental plugin for almost all server-end applications. It was implemented and added into libapidbc beforehand because of its wide use. libapidbc has established a firm foundation for the nano-SOA architecture, by offering the key components like IPlugin, API Nexus and DBC. nano-SOA, SOA and AIO are not mutually exclusive options. In real use cases, users can work out the optimum design through combination of these three architecture patterns. For time-consuming asynchronous operations (like video transcoding) without the need to wait for a result to be returned, it is a preferred option to deploy it as an independent service to a dedicated server cluster with acceleration hardware installed, because most of the consumptions are used for video encoding and decoding. It is unnecessary to add it into an App Server as a plugin. |
BaiY Port Switch Service (BYPSS) is designed for providing a high available, strongly consistent and high performance distributed coordination and message dispatching service based on the quorum algorithm. It can be used to provide services such as fault detection, service election, service discovery, distributed lock, and other distributed coordination functionalities, it also integrates a message routing service. Thanks for our patented algorithm, we eliminate the network broadcast, disk IO and other major costs within the traditional Paxos / Raft algorithms. We have also done a lot of other optimizations, such as: support for batch mode, use the concurrent hash table and high performance IO component. These optimizations allow BYPSS to support ultra-large-scale computing clusters consist with millions nodes and trillions ports in a limited (both for throughput and latency) cross-IDC network environment (See: 5.4.3 Port Switch Service). Scaling out nodes across multiple active IDC and keeping strong consistency guarantee is the key technology of modern high-performance and high-availability cluster, which is also recognized as the main difficulty in the industry. As examples: September 4, 2018, the cooling system failure of a Microsoft data center in South Central US caused Office, Active Directory, Visual Studio and other services to be offline for nearly 10 hours; August 20, 2015 Google GCE service interrupted for 12 hours and permanently lost part of data; May 27, 2015, July 22, 2016 and Dec 5, 2019 Alipay interrupted for several hours; As well as the July 22, 2013 and Mar 29, 2023 WeChat service interruption for several hours, and etc. These major accidents are due to product not implement the multiple active IDC architecture correctly, so a single IDC failure led to full service off-line. Distributed coordination service
Distributed coordination services provide functions such as service discovery, service election, fault detection, failover, failback, distributed lock, task scheduling, message routing and message dispatching. The distributed coordination service is the brain of a distributed cluster that is responsible for coordinating all the server nodes in the cluster. Make distributed clusters into an organic whole that works effectively and consistently, making it a linear scalable high performance (HPC) and high availability (HAC) distributed clustering system.
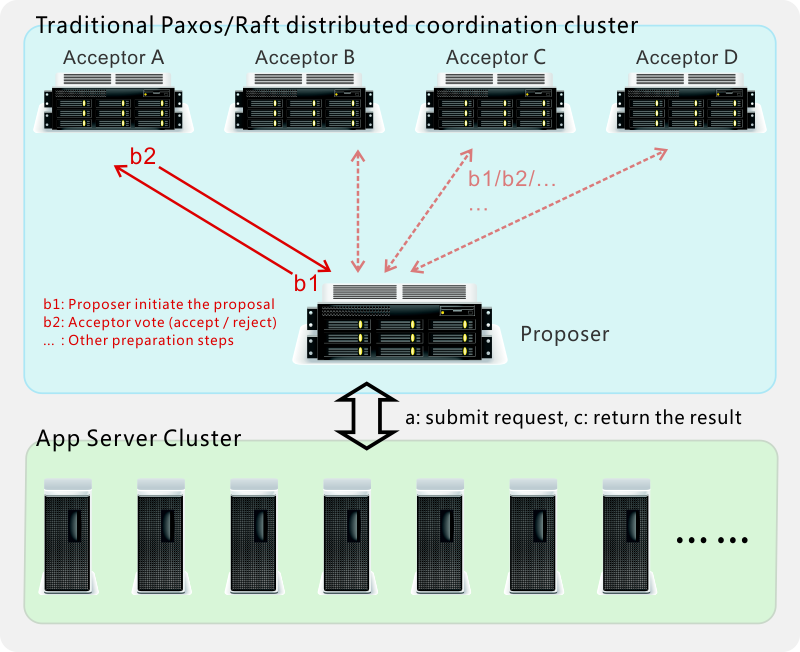
The traditional Paxos / Raft distributed coordination algorithm initiates voting for each request, generating at least 2 to 4 broadcasts (b1, b2...) and multiple disk IO. Making it highly demanding on network throughput and communication latency, and cannot be deployed across multiple data centers. Our patent algorithm completely eliminated these overheads. Thus greatly reducing the network load, significantly improve the overall efficiency. And makes it easy to deploy clusters across multiple data centers.
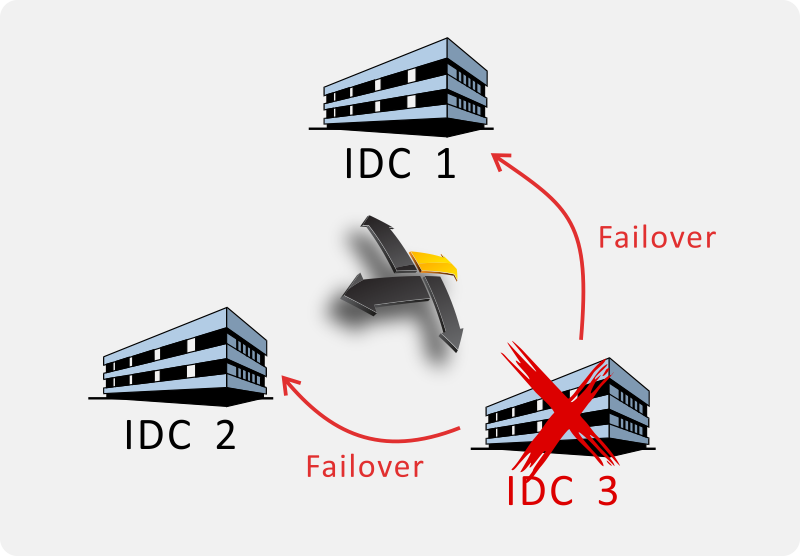
Based on our unique distributed coordination technology, the high performance, strong consistency cluster across multiple data centers can be implemented easily. Fault detection and failover can be done in milliseconds. The system is still available even if the entire data center is offline. We also providing a strong consistency guarantee: even if there is a network partition, it will not appear split brain and other data inconsistencies. For example:
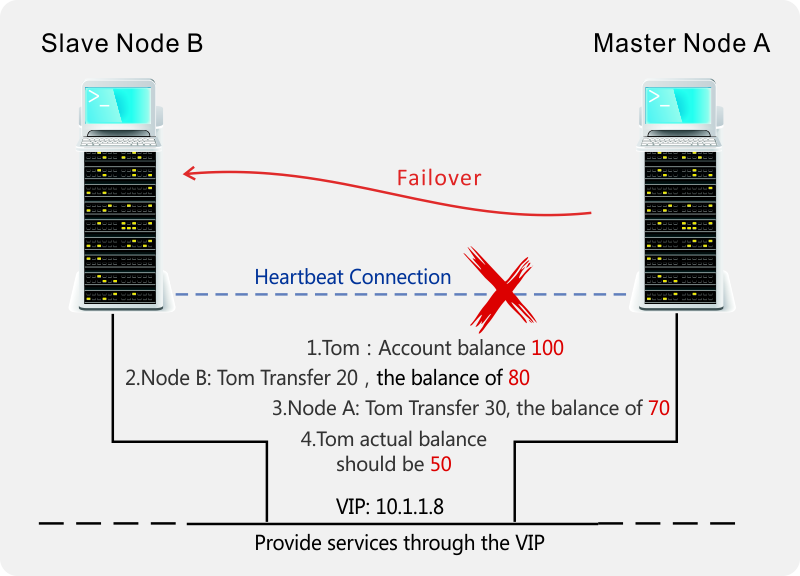
In the traditional dual fault tolerance scheme, the slave node automatically promotes itself as the master node after losing the heartbeat signal and continues to provide services to achieve high availability. In this case, split brain problem occurs when both the master and slave nodes are normal, but the heartbeat connection is accidentally disconnected (network partition). As shown in above Figure: At this time, node A and B both think that the other party is offline. As a result, both nodes upgrade themselves to the master node and provide the same service, respectively. This will result in inconsistent data that is difficult to recover. Our BYPSS service provides the same level of consistency as the traditional Paxos / Raft distributed algorithm, fundamentally eliminates the occurrence of inconsistencies such as split brain. Similarly: ICBC, Alipay and other services are also have its own remote disaster recovery solutions (Alipay: Hangzhou → Shenzhen, ICBC: Shanghai → Beijing). However, in their remote disaster recovery schemes, there is no paxos and other distributed coordination algorithms between the two data centers, so strong consistency cannot be achieved. For example, a transfer transaction that has been successfully completed at Alipay may take several minutes or even hours to be synchronized from the Hangzhou main IDC to the disaster recovery center in Shenzhen. When the Hangzhou main data center offline, all of these non-synchronized transactions are lost if they switch to the disaster recovery center, leads a large number of inconsistencies. Therefore, ICBC, Alipay and other institutions would rather stop the service for hours or even longer, and would not be willing to switch to the disaster recovery center in the major accidents of the main IDC. Operators will consider turning their business into a disaster recovery center only after a devastating accident such as a fire in the main data center. Therefore, the remote disaster recovery schemes and our strong consistency, high availability, anti-split brain multi-IDC solution is essentially different. In addition, Paxos / Raft cannot guarantee the strong consistency of data during the process of simultaneous failure and recovery of more than half of the nodes, and may cause inconsistencies such as phantom reading (For example, in a three-node cluster, node A goes offline due to power failure, and after one hour, nodes B and C go offline because of disk failure. At this point, node A resumes power supply and goes online again, and then the administrator replaces the disks of nodes B and C and restores them to go online. At this point, the data modification of the entire cluster in the last hour will be lost, and the cluster will fall back to the state before the A node goes offline at 1 hour ago). BYPSS fundamentally avoids such problems, so BYPSS has a stronger consistency guarantee than Paxos / Raft. Due to the elimination of a large number of broadcast and distributed disk IO and other high-cost operation brought by the Paxos / Raft algorithm. Making BYPSS distributed coordination component also provides more excellent features in addition to the above advantages: Bulk operation: Allows each network packet to contain a large number of distributed coordination requests at the same time. Network utilization greatly improved, from the previous less than 5% to more than 99%. Similar to the difference between a flight only can transport one passenger each time, and another one can transport full of passengers. In the actual test, in a single Gigabit network card, BYPSS can achieve 4 million requests per second performance. In the dual-port 10 Gigabit network card (currently the mainstream data center configuration), the throughput of 80 million requests per second can be reached. There is a huge improvement compared to the Paxos / Raft cluster which performance is usually less than 200 requests per second (restricted by its large number of disk IO and network broadcast). Large capacity: usually every 10GB of memory can support at least 100 million ports. In a 1U-size entry-level PC Server with 64 DIMM slots (8TB), it can support at least 80 billion objects at the same time. In a 32U large PC server (96TB), it can support about 1 trillion distributed coordinating objects. In contrast, traditional Paxos / Raft algorithms can only effectively manage and schedule hundreds of thousands of objects due to their limitations. The essence of the problem is that in algorithms such as Paxos / Raft, more than 99.99% of the cost is spent on broadcast (voting) and disk writes. The purpose of these behaviors is to ensure the reliability of the data (data needs to be stored on persistent devices on most nodes simultaneously). However, distributed coordination functions such as service discovery, service election, fault detection, failover, failback, distributed lock, and task scheduling are all temporary data that have no long-term preservation value. So it makes no sense to spend more than 99.99% of your effort to persist multiple copies of them - even if there is a rare disaster that causes the main node to go offline, we can regenerate the data in an instant with great efficiency. It's as if tom bought a car that has an additional insurance service. The terms are: In the event of a fatal traffic accident, it provides a back in time mechanism that takes tom back to the moment before the accident, so he can avoid this accident. Of course, such a powerful service is certainly expensive, and it probably needs to prepay all the wealth tom's family can get in the next three generations. And these prepaid service fees are not deductible even if he has never had a fatal traffic accident with this car. Such an expensive service that is unlikely to be used in a lifetime (what percentage of people will have fatal traffic accidents? Not to mention that it can only happen on the specific car), even if it does happen, this huge price is hard to say is worth it? And we offer a different kind of additional service for our cars: Although there is no back in time function, our service can instant and intact resurrect all the victims in the same place after the fatal accident. The most important thing is that the service will not charge any fees in advance. Tom only needs to pay a regenerative technology service fee equivalent to his half-month salary after each such disaster. In summary, our patented distributed coordination algorithm providing strong consistency and high availability assurance at the same level as the traditional Paxos / Raft algorithm. At the same time, it also greatly reduces the system's dependence on the network and disk IO, and significantly improves the overall system performance and capacity. This is a significant improvement in the high availability (HAC) and high performance (HPC), large-scale, strongly consistent distributed clusters. Technical principleBaiY Port Switch Service (BYPSS, pronounced "bypass") is designed for providing a high available, strongly consistent and high performance distributed coordination and message dispatching service which supports one trillion level ports, one million level nodes, and ten millions to billions of messages processed per second. The key concepts of the service include:
BYPSS offers the following API primitives:
Client connections within BYPSS are categorized into two types:
Compared with traditional distribute coordination service and messaging middleware products, the port switch service has the following characteristics:
BYPSS itself is a message routing service that integrates fault detection, service election, service discovery, distributed lock, and other distributed coordination functionalities. It has achieved superior performance and concurrency at the premise of strong consistency, high availability and scalability (scale-out), by sacrificing reliability in extreme conditions. BYPSS can be treated as a cluster coordination and message dispatching service customized for nano-SOA architecture. The major improvement of nano-SOA is, the model that each user request needs to involve multiple service nodes is improved so that most of user requests need to involve only different BMOD in the same process space. In addition to making deployment and maintenance easier and the delay for request processing dramatically reduced, the above improvement also brings the following two benefits:
BYPSS allows for a few messages to be lost in extreme conditions, for the purpose of avoiding disk writing and master/slave copying and promoting efficiency. This is a reasonable choice for nano-SOA. Reliability Under Extreme ConditionsTraditional distributed coordination services are usually implemented using quorum-based consensus algorithms like Paxos and Raft. Their main purpose is to provide applications with a high-availability service for accessing distributed metadata KV. The distributed coordination services such as distributed lock, message dispatching, configuration sharing, role election and fault detection are also offered. Common implementations of distributed coordination services include Google Chubby (Paxos), Apache ZooKeeper (Fast Paxos), etcd (Raft), Consul (Raft+Gossip), and etc. Poor performance and high network consumption are the major problems with consensus algorithms like Paxos and Raft. For each access to these services, either write or read, it requires 2 to 4 times of broadcasting within the cluster to confirm in voting manner that the current access is acknowledged by the quorum. This is because the master node needs to confirm it has the support from the majority while the operation is happening, and to confirm it remains to be the legal master node. In real cases, the overall performance is still very low and has strong impact to network IO, though the read performance can be optimized by degradation the overall consistency of the system or adding a lease mechanism. If we look back at the major accidents happened in Google, Facebook or Twitter, many of them are caused by network partition or wrong configuration (human error). Those errors lead to algorithms like Paxos and Raft broadcasting messages in an uncontrollable way, thus driving the whole system crashed. Furthermore, due to the high requirements of network IO (both throughput and latency), for Paxos and Raft algorithm, it is difficult (and expensive) to deploy a distributed cluster across multiple data centers with strong consistency (anti split brain) and high availability. For example: September 4, 2018, the cooling system failure of a Microsoft data center in South Central US caused Office, Active Directory, Visual Studio and other services to be offline for nearly 10 hours; Google GCE service was disconnected for 12 hours and lost some data permanently on August 20, 2015; Alipay was interrupted for several hours on May 27, 2015, July 22, 2016 and Dec 5, 2019; July 22, 2013 WeChat service interruption Hours; and May 2017 British Airways paralyzed for a few days and other major accidents both are due to the single IDC dependency. Because most of the products that employ SOA architecture rely on messaging middleware to guarantee the overall consistency, they have strict requirements for availability (part of nodes failed will not affect normal operation of the system), reliability (ensures messages are in order and never repeated/lost even when part of nodes failed), and functionality (e.g., publish-subscribe pattern, distributing the tasks in a round-robin fashion). It is inevitable to use technologies that have low performance but require high maintenance cost, such as high availability cluster, synchronization and copy among nodes, and data persistence. Thus the message dispatching service often becomes a major bottleneck for a distributed system. Compared with Paxos and Raft, BYPSS also provides distributed coordination services such as fault detection, service election, service discovery and distributed lock, as well as comparable consensus, high availability, and the capability of resisting split-brain. Moreover, by eliminates nearly all of the high cost operations like network broadcast and disk IO, it has far higher performance and concurrency capability than Paxos and Raft. It can be used to build large-scale distributed cluster system across multiple data centers with no additional requirements of the network throughput and latency. BYPSS allows for tens of millions of messages to be processed per second by a single node, and guarantees that messages are in order and never repeated, leaving common middleware far behind in terms of performance. While having absolute advantages from performance perspective, BYPSS has to make a trade-off. The compromise is the reliability in extreme conditions (two times per year on average; mostly resulted from maintenance; controlled within low-load period; based on years of statistics in real production environments), which has the following two impacts to the system:
In brief, we can treat BYPSS as a cluster coordination and message dispatching service customised for the nano-SOA architecture. BYPSS and nano-SOA are mutually complementary. BYPSS is ideal for implementing a high performance, high availability, high reliability and strong consistency distributed system with nano-SOA architecture. It can substantially improve the overall performance of the system at the price of slightly affecting system performance under extreme conditions. BYPSS CharacteristicsThe following table gives characteristic comparisons between BYPSS and some distributed coordination products that utilize traditional consensus algorithms like Paxos and Raft.
Among the above comparisons, delay and performance mainly refers to write operations. This is because almost all of the meaningful operations associated with a typical distributed coordination tasks are write operations. For example:
As shown in the above table, the port registration in BYPSS corresponds to "write/create KV pair" in traditional distributed coordination products. The port unregistration corresponds to "delete KV pair", and the unregistration notification corresponds to "change notification". To achieve maximum performance, we will not use read-only operations like query in production environments. Instead, we hide query operations in write requests like port registration. If the request is successful, the current node will become the owner. If registration failed, the current owner of the requested service will be returned. This has also completed the read operations like owner query (service discovery / name resolution). It is worth noting that even a write operation (e.g., port registration) failed, it is still accompanied by a successful write operation. The reason is: There is a need to add the current node that initiated the request into the change notification list of specified item, in order to push notification messages to all interested nodes when a change such as port unregistration happens. So the write performance differences greatly affect the performance of an actual application. BYPSS based High performance clusterFrom the high-performance cluster (HPC) perspective, the biggest difference between BYPSS and the traditional distributed coordination products (described above) is mainly reflected in the following two aspects:
Due to the performance and capacity limitations of traditional distributed coordination services, in a classical distributed cluster, the distributed coordination and scheduling unit is typically at the service or node level. At the same time, the nodes in the cluster are required to operate in stateless mode as far as possible .The design of service node stateless has low requirement on distributed coordination service, but also brings the problem of low overall performance and so on. BYPSS, on the other hand, can easily achieve the processing performance of tens of millions of requests per second, and trillions of message ports capacity. This provides a good foundation for the fine coordination of distributed clusters. Compared with the traditional stateless cluster, BYPSS-based fine collaborative clusters can bring a huge overall performance improvement. User and session management is the most common feature in almost all network applications. We first take it as an example: In a stateless cluster, the online user does not have its owner server. Each time a user request arrives, it is routed randomly by the reverse proxy service to any node in the backend cluster. Although LVS, Nginx, HAProxy, TS and other mainstream reverse proxy server support node stickiness options based on Cookie or IP, but because the nodes in the cluster are stateless, so the mechanism simply increases the probability that requests from the same client will be routed to a certain backend server node and still cannot provide a guarantee of ownership. Therefore, it will not be possible to achieve further optimizations. While benefiting from BYPSS's outstanding performance and capacity guarantee, clusters based on BYPSS can be coordinated and scheduled at the user level (i.e.: registering one port for each active user) to provide better overall performance. The implementation steps are:
Compared with traditional architectures, taking into account the stateless services also need to use MySQL, Memcached or Redis and other stateful technologies to implement the user and session management mechanism, so the above implementation does not add much complexity, but the performance improvement is very large, as follows:
It is worth mentioning that such a precise collaborative algorithm does not cause any loss in availability of the cluster. Consider the case where a node in a cluster is down due to a failure: At this point, the BYPSS service will detect that the node is offline and automatically release all users belonging to that node. When one of its users initiates a new request to the cluster, the request will be routed to the lightest node in the current cluster (See step 2-b-i in the foregoing). This process is transparent to the user and does not require additional processing logic in the client. The above discussion shows the advantages of the BYPSS HPC cluster fine coordination capability, taking the user and session management functions that are involved in almost all network applications as an example. But in most real-world situations, the application does not just include user management functions. In addition, applications often include other objects that can be manipulated by their users. For example, in Youku.com, tudou.com, youtube.com and other video sites, in addition to the user, at least some "video objects" can be played by their users. Here we take the "video object" as an example, to explore how the use the fine scheduling capabilities of BYPSS to significantly enhance cluster performance. In this hypothetical video-on-demand application, similar to the user management function described above, we first select an owner node for each active video object through the BYPSS service. Secondly, we will divide the properties of a video object into following two categories:
In addition, we also stipulate that any write operation to the video object (whether for common or dynamic properties) must be done by its owner. A non-owner node can only read and cache the common properties of a video object; it cannot read dynamic properties and cannot perform any update operations. Therefore, we can simply infer that the general logic of accessing a video object is as follows:
Compared with the classic stateless SOA cluster, the benefits of the above design are as follows:
Similar to the previously mentioned user management case, the precise collaboration algorithm described above does not result in any loss of service availability for the cluster. Consider the case where a node in a cluster is down due to a failure: At this point, the BYPSS service will detect that the node is offline and automatically release all videos belonging to that node. When a user accesses these video objects next time, the server node that received the request takes ownership of the video object from BYPSS and completes the request. At this point, the new node will (replace the offline fault node) becomes the owner of this video object (See step 2-c-i in the foregoing). This process is transparent to the user and does not require additional processing logic in the client. The above analysis of "User Management" and "Video Services" is just an appetizer. In practical applications, the fine resource coordination capability provided by BYPSS through its high-performance, high-capacity features can be applied to the Internet, telecommunications, Internet of Things, big data processing, streaming computing and other fields. We will continue to add more practical cases, for your reference. |
The BaiY Distributed Message Queuing Service (BYDMQ, pronounced "by dark") is a distributed message queue service with strong consistency, high availability, high throughput, low latency and linear scale-out. It can support a single point of tens of millions of concurrent connections and a single point of tens of millions of message forwarding performance per second, and supports linear horizontal scaling out of the cluster. BYDMQ itself also relies on BYPSS to perform distributed coordination such as service elections, service discovery, fault detection, distributed locks, and message dispatching. Although BYPSS also includes high-performance message routing and dispatching functions, its main design goal is to deliver distributed coordination-related control-type signals such as task scheduling. On the other hand, BYDMQ is focused on high-throughput, low-latency, large-scale business message dispatching. After the business related messages are offloaded to BYDMQ, the work pressure of BYPSS can be greatly reduced.
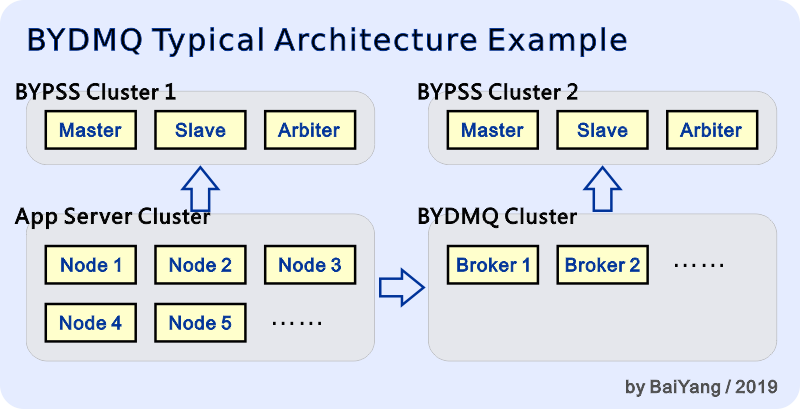
As shown in above figure, in the typical use case, BYDMQ and App Server cluster each have their own BYPSS cluster which are responsible for their respective distributed coordination tasks. The App cluster relies on BYPSS1 to complete distributed coordination, while its message communication relies on the BYDMQ cluster. However, App Server and BYDMQ clusters can also share the same BYPSS service in a development / test environment, or a production environment with small business volume. It should also be noted that the "independent cluster" described herein refers only to logical independence. Physically, even two logically independent BYPSS clusters can share physical resources. For example, an Arbiter node can be shared by multiple BYPSS clusters; even Master and Slave nodes in two BYPSS clusters can become backup nodes of each other. This simplifies the operation and maintenance management burden, and effectively save resources such as server hardware and energy consumption. Before we continue to introduce the main features of BYDMQ, we first need to clarify a concept: the reliability of message queue (message middleware, MQ). As we all know, "reliable messaging" consists of three elements: the delivery process can be called reliable only if there are no missing, unordered or duplicate messages. Regrettably, there is currently no real message queue product that satisfies the above three conditions at the same time. Or in other words, It is impractical to implement a message queue product that satisfies all of the above three elements within an acceptable cost range. To illustrate this issue, consider the following case:
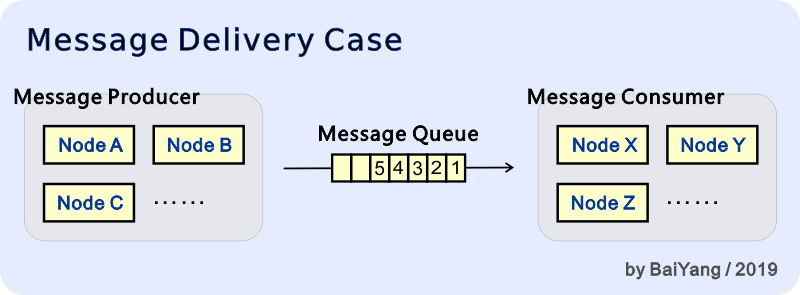
As shown in the figure above, in this case, the message producer consists of nodes A, B, and C, the message consumer contains nodes X, Y, and Z, and the producers deliver messages to consumers through a message queue. Now the message producer has produced 5 messages and successfully submitted them to the message queue in sequence. Under such circumstances, let's discuss the reliability of message delivery one by one:
It can be seen from the above discussion that at this stage, there is no MQ product that provides reliable delivery of messages at reasonable cost. Under this premise, the current solution mainly relies on App Server's own business logic (such as: idempotent operation, persistent state machine, etc.) algorithm to overcome these problems. Conversely, no matter how "reliable" MQ product is used, the current App business logic also needs to deal with and overcome the above-mentioned unreliable delivery of messages. Since MQ is not reliable in its essence, and the App has overcome these unreliability, why bother to reduce the performance by thousands or even tens of thousands of times to support the "distributed storage + ACK" mechanism at the MQ layer at all? Based on the above ideas, BYDMQ does not provide so-called (actually unachievable) "reliability" guarantees like products such as RabbitMQ and RocketMQ. In contrast, BYDMQ adopts the "best effort delivery" mode to ensure that messages are delivered as reliably as possible without compromising performance. As mentioned earlier, the App has overcome the occasional unreliability of messaging. Therefore, such a design choice greatly improves the performance of the whole system, and does not actually increase the development workload of the business logic. Based on the above design concept, BYDMQ includes the following features:
In summary, BYDMQ sacrifices the reliability of the message that cannot be guaranteed by a certain degree, combined with message packing, pipelining, and direct delivery by the owner, greatly improves the single point performance of the message queue service. At the same time, thanks to the strong consistent, high-availability, and high-performance distributed cluster computing ability introduced by BYPSS, it also has excellent linear scale-out capability. In addition, its flexible control of each message, as well as the characteristics of dispersion delivery, ultimately provide users with an ultra-high performance, high-quality distributed message queue product. |
Note1: This article is
excerpted from
"nano-SOA - libapidbc" section in "BaiY
Application Platform White Paper"。
Note2: The above nano-SOA architecture and the BYPSS distributed coordination algorithm are all subject to a number of national and international patents protections.
Copyright (C) 2016 - 2022, Bai Yang (baiy.cn). All Rights
Reserved.